”大数据 spark hadoop“ 的搜索结果
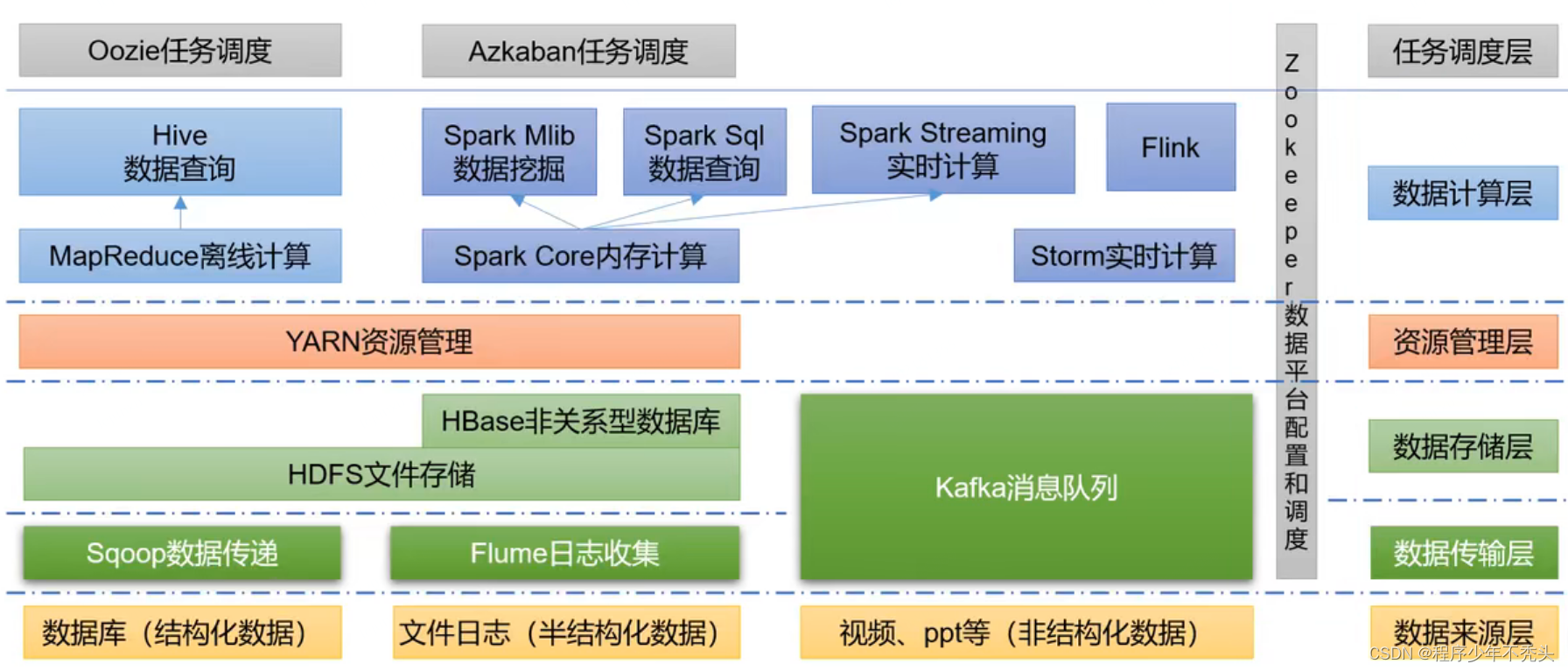
Spark,是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。 Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互...
实战大数据|Hadoop|Spark|Flink|离线计算|实时计算课程分享下载

大数据系列内部培训经典内容,包括大数据系列架构,大数据Hadoop系列、Spark、Hive、Storm、Hbase、Sqoop......
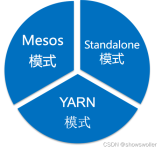
大数据Spark面试题汇总,共有79道面试题以及题目的解答 部分题目如下: 1. spark 的有几种部署模式,每种模式特点? 2. Spark 为什么比 mapreduce 快? 3. 简单说一下 hadoop 和 spark 的 shuffle 相同和差异? 5. ...


大数据时代Hadoop和Spark技术研究.docx
Hadoop只是一种处理大数据的技术手段。 “大数据”概念在1980年由维克托·迈尔-舍恩伯格及肯尼斯·库克耶 在《第三次浪潮》首次提出,由麦肯锡公司(McKinsey)最早应用。 大数据的特征 1,容量:数据的大小...
大数据Spark企业级实战
标签: spark
《大数据Spark企业级实战》详细解析了企业级Spark开发所需的几乎所有技术内容,涵盖Spark的架构设计、Spark的集群搭建、Spark内核的解析、Spark SQL、MLLib、GraphX、Spark Streaming、Tachyon、SparkR、Spark多语言...
CDH6全套资源安装包、CDH6、大数据平台、hadoop、spark、kafka、大数据技术、数据仓库、hive、hdfs、大数据技术架构、数据平台管理、开源大数据平台、大数据安装包、CDH安装教程
[大数据]Hadoop+Storm+Spark全套入门及实战视频教程-附件资源
HBase、 Java9 、Java10 、MySQL优化 、JVM原理 、JUC多线程、 CDH版Hadoop Impala、 Flume 、Sqoop、 Azkaban、 Oozie、 HUE、 Kettle、 Kylin 、Spark 、Mllib机器学习、 Flink、 Python、 SpringBoot、 Hadoop3.x...
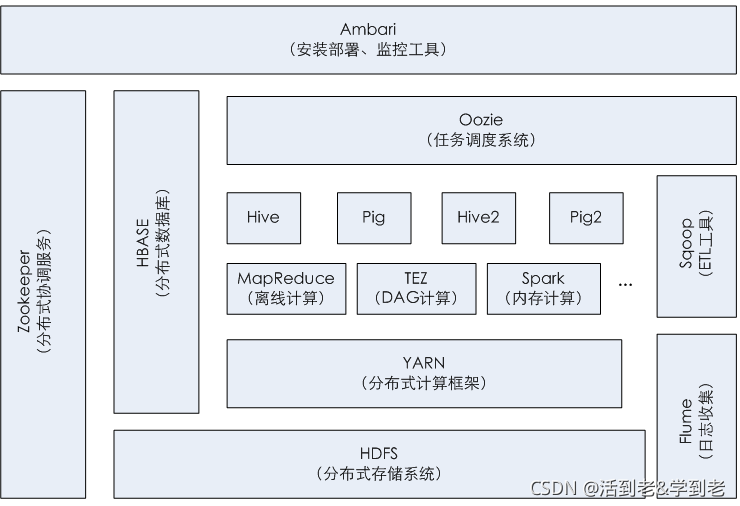
大数据是一系列技术的...Hadoop是一个由Apache基金会所开发的分布式系统基础架构,是用Java语言开发的一个开源分布式计算平台,适合大数据的分布式存储和计算平台。 广义上讲,大数据是时代发展和技术进步的产物...

学习着数据科学与大数据技术专业(简称大数据)的我们,对于“大数据”这个词是再熟悉不过了,而每当我们越去了解大数据就越发现有个词也会一直被提及那就是——Hadoop 那Hadoop与大数据有什么关系呢? 所谓...
大数据Hadoop权威指南,pdf,中英文版。第4版 The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. The Apache Hadoop software library is a framework...
大数据 hadoop spark hbase ambari全套视频教程(购买的付费视频)
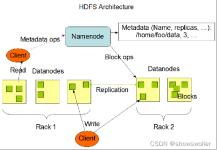
海量数据的存储问题很早就已经出现了,一些行业或者部门因为历史的积累,数据量也达到了一定的级别。很早以前,当一台电脑无法存储这么庞大的数据时,采用的解决方案是使用NFS(网络文件系统)将数据分开存储。...

目前,Hadoop、MapReduce和Spark等分布式处理方式已经成为大数据处理各环节的通用处理方法。 Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。...
通过Python强大的数据处理库和易用的编程语法,我们可以处理和分析大规模...在本文中,我们将探讨Python在大数据领域的应用,重点介绍Hadoop、Spark和Pyspark,并分享一些数据处理的技巧。# 将结果写入Parquet文件。
工作之余,我收集了不少大数据方面的PDF电子书,书目如下,持续更新中。。。 很多都是经典,不敢独享,跟大家分享下。有需要的请关注文末的微信公众号,发送消息“大数据电子书”获取下载链接 Hadoop权威指南 ...
大数据之hadoop,spart全套全技术栈视频课程,包含spark,hadoop,storm,kafka,mllib等组件的安装,编程等,依次从基础,进阶直到实际实践。

推荐文章
- 如何将xml转换为json_xml转json-程序员宅基地
- TCP 的那些事 | TCP报文格式解析_.tcp文件是图片吗-程序员宅基地
- python——stack()和unstack()用法_unstack函数-程序员宅基地
- C语言调用sqlite3命令语句实现将txt文件导入到数据库中_从txt导入到sqlite-程序员宅基地
- AOP与OOP有什么区别,谈谈AOP的原理是什么,大厂Android高级面试题汇总解答-程序员宅基地
- 最小费用流_单向图费用流-程序员宅基地
- Python中的5个高阶概念属性的知识点!你要了解明白哦!_python属性的五大类-程序员宅基地
- python 基于PHP+MySQL的装修网站的设计与实现_python抓取装修需求-程序员宅基地
- ubuntu完美的nvidia驱动安装方式(ubuntu16+驱动410+cuda10.0)or(ubuntu16+驱动455+cuda11.1)_乌班图英伟达驱动选着哪个版本-程序员宅基地
- 解决redis超时io.lettuce.core.RedisCommandTimeoutException: Connection timed out after 5s-程序员宅基地